AiDex

![]()
![]()
![]()

The persistent brain for AI coding agents.
AiDex is an MCP server that gives AI coding assistants a memory, semantic search, and live telemetry — local-first, model-agnostic. Works with any MCP-compatible AI assistant: Claude Code, Claude Desktop, Cursor, Windsurf, Gemini CLI, VS Code Copilot, and more.
Three Pillars
🧠 Memory — Tasks, notes, and session-notes survive every chat. Auto-logged history, scheduled tasks, cross-session continuity. Your AI knows tomorrow what mattered today.
🔍 Search — Three modes: exact (identifier), semantic (concept), hybrid (RRF fusion of both). Embeds code, docs, and workspace items into one ranking. Cross-project — every repo in one query. Optional LLM layer translates non-English queries and reranks results.
🌐 Telemetry — LogHub receives live logs from any app via HTTP (no SDK). The AI watches what your code actually does, not just what it says. Live-streamed in the Viewer.
<details> <summary><strong>And yes — it's still 50× more token-efficient than grep.</strong></summary>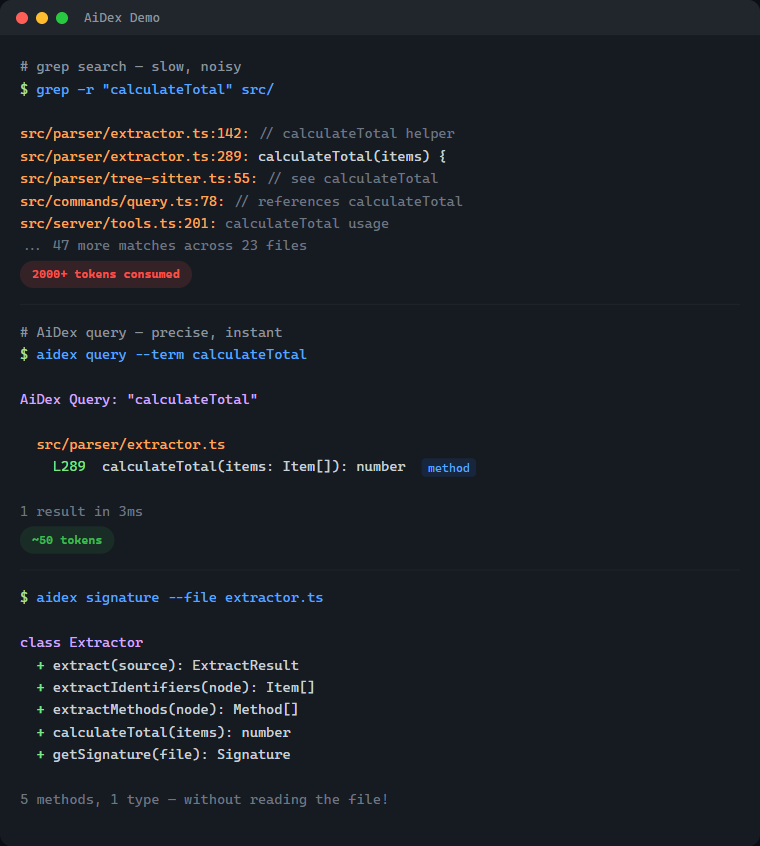
| Without AiDex | With AiDex | |
|---|---|---|
Find PlayerHealth | Grep → 200 hits in 40 files → reads 5 files → 2,000+ tokens | 1 query → 3 exact locations → ~50 tokens |
| Get file structure | Reads entire 500-line file → 1,500 tokens | Signatures → classes + methods → ~80 tokens |
| What changed today? | git diff + grep + context → 3,000+ tokens | Time-filtered query → ~50 tokens |
What's Inside — 33 Tools in One Server
| Category | Tools | What it does |
|---|---|---|
| Semantic Search 🆕 | search, settings | Hybrid / semantic / exact retrieval over code, docs & workspace. Settings tab to configure embeddings + LLM layer |
| Index & Identifier Search | init, query, update, remove, status | Index your project, search identifiers by name (exact/contains/starts_with), time-based filtering |
| Signatures | signature, signatures | Get classes + methods of any file without reading it — single file or glob pattern |
| Project Overview | summary, tree, describe, files | Entry points, language breakdown, file tree with stats, file listing by type |
| Cross-Project | link, unlink, links, scan | Link dependencies, discover indexed projects |
| Global Search | global_init, global_query, global_signatures, global_status, global_refresh | Search identifiers across ALL your projects — "Have I ever written X?" |
| Guidelines | global_guideline | Persistent AI instructions & coding conventions — shared across all projects |
| Sessions | session, note | Track sessions, detect external changes, leave notes for next session (with searchable history) |
| Task Backlog | task, tasks | Built-in task management with priorities, tags, auto-logged history, and scheduled/recurring tasks |
| Log Hub | log | Universal log receiver — any program sends logs via HTTP, queryable by the AI, live in Viewer |
| Screenshots | screenshot, windows | Cross-platform screen capture with LLM optimization — scale + color reduction saves up to 95% tokens |
| Viewer | viewer | Interactive browser UI with file tree, signatures, tasks, logs, search, and live reload |
12 languages — C#, TypeScript, JavaScript, Rust, Python, C, C++, Java, Go, PHP, Ruby, HCL/Terraform
<details> <summary><strong>Quick Examples</strong> — see it in action</summary># Find where "PlayerHealth" is defined — 1 call, ~50 tokens
aidex_query({ term: "PlayerHealth" })
→ Engine.cs:45, Player.cs:23, UI.cs:156
# All methods in a file — without reading the whole file
aidex_signature({ file: "src/Engine.cs" })
→ class GameEngine { Update(), Render(), LoadScene(), ... }
# What changed in the last 2 hours?
aidex_query({ term: "render", modified_since: "2h" })
# Search across ALL your projects at once
aidex_global_query({ term: "TransparentWindow", mode: "contains" })
→ Found in: LibWebAppGpu (3 hits), DebugViewer (1 hit)
# Leave a note for your next session
aidex_note({ path: ".", note: "Test the parser fix after restart" })
# Create a task while working
aidex_task({ path: ".", action: "create", title: "Fix edge case in parser", priority: 1, tags: "bug" })Table of Contents
- What's Inside
- Semantic Search & LLM Layer 🆕
- The Problem
- The Solution
- Why Not Just Grep?
- How It Works
- Features
- Supported Languages
- Quick Start
- Available Tools
- Time-based Filtering
- Project Structure
- Session Notes
- Task Backlog
- Global Search
- AI Guidelines
- Log Hub
- Debug Dashboard
- Screenshots — LLM-Optimized
- Interactive Viewer
- CLI Usage
- Performance
- Technology
- Contributing
- License
Semantic Search & LLM Layer
v2.0 added semantic search via locally-run embeddings — your AI can find a function even when it doesn't know the exact identifier.
Three modes — pick the right tool for the question
| Mode | What it does | When to use |
|---|---|---|
exact | Identifier match (same as aidex_query) | You know the name. PlayerHealth → 3 hits |
semantic | Vector KNN over embedded code+docs+workspace | You know the concept. "how do we cache the model" → finds getQueryEmbedder |
hybrid (default) | RRF fusion of both | Mixed queries. Robust by default |
What gets embedded
- Code — every method and type, three-tier chunking (signature + doc-comment + weighted identifier bag)
- Docs — Markdown sections (README, CHANGELOG, docs/, plan files), split at heading boundaries
- Workspace — tasks, task logs, session notes, archived note history
One ranking, all kinds. A query like "how to write logs from external programs" surfaces the README's ## Log Hub section first, then the log method in commands/log.ts, then any related task.
Setup
// Enable embeddings on a project (one-time, ~30s for AiDex itself, cached afterwards)
aidex_init({ path: ".", embeddings: true })
// Search
aidex_search({ query: "how do we batch requests to the LLM", path: "." })
aidex_search({ query: "retry with backoff", scope: "all" }) // across every embedded projectOr use the Settings tab in the Viewer (aidex_settings({ path: ".", open: true })) — toggles for embeddings, LLM provider, model, and the privacy switch.
Optional LLM layer
When an Anthropic / OpenAI / OpenRouter / Ollama / HuggingFace API key is configured, AiDex can:
- Translate non-English queries → "wie speichere ich Logs lokal" finds the right code
- Expand vague queries into 2-4 concrete subqueries (RRF-merged)
- Rerank top-N retrieval candidates
Privacy switch llm_send_code defaults to off — only your literal query and metadata (paths, names, anchors) are sent. Code bodies stay local. Per-project, easy to verify in Settings.
Local-first: works fully offline with pure embeddings. The LLM layer is opt-in, never required.
The Problem
Every time your AI assistant searches for code, it:
- Greps through thousands of files → hundreds of results flood the context
- Reads file after file to understand the structure → more context consumed
- Forgets everything when the session ends → repeat from scratch
A single "Where is X defined?" question can eat 2,000+ tokens. Do that 10 times and you've burned half your context on navigation alone.
The Solution
Index once, query forever:
# Before: grep flooding your context
AI: grep "PlayerHealth" → 200 hits in 40 files
AI: read File1.cs, File2.cs, File3.cs...
→ 2000+ tokens consumed, 5+ tool calls
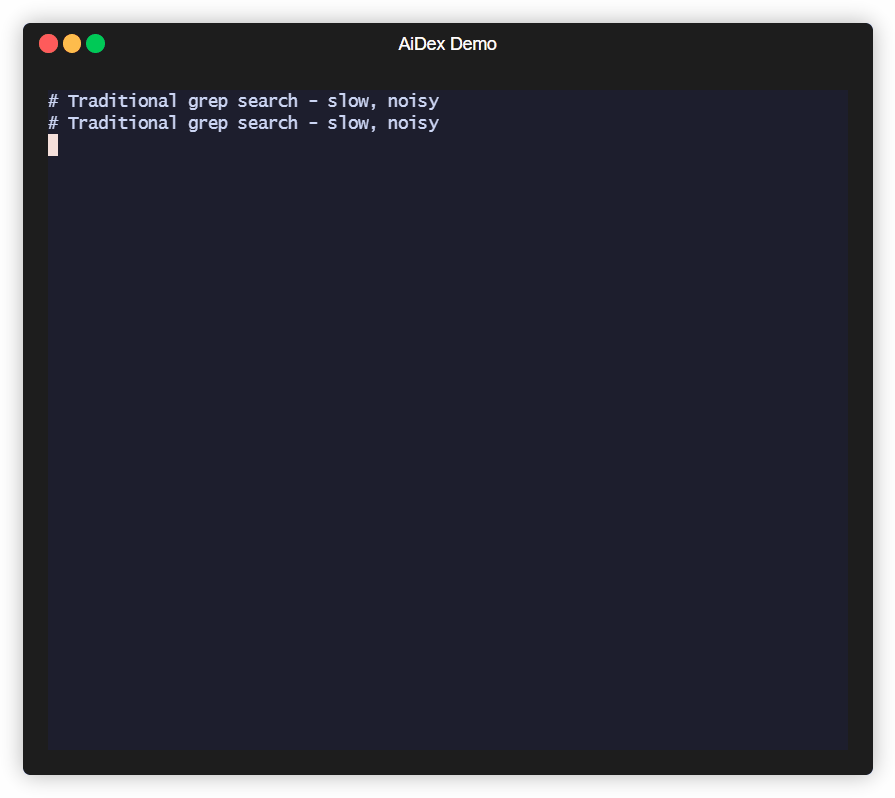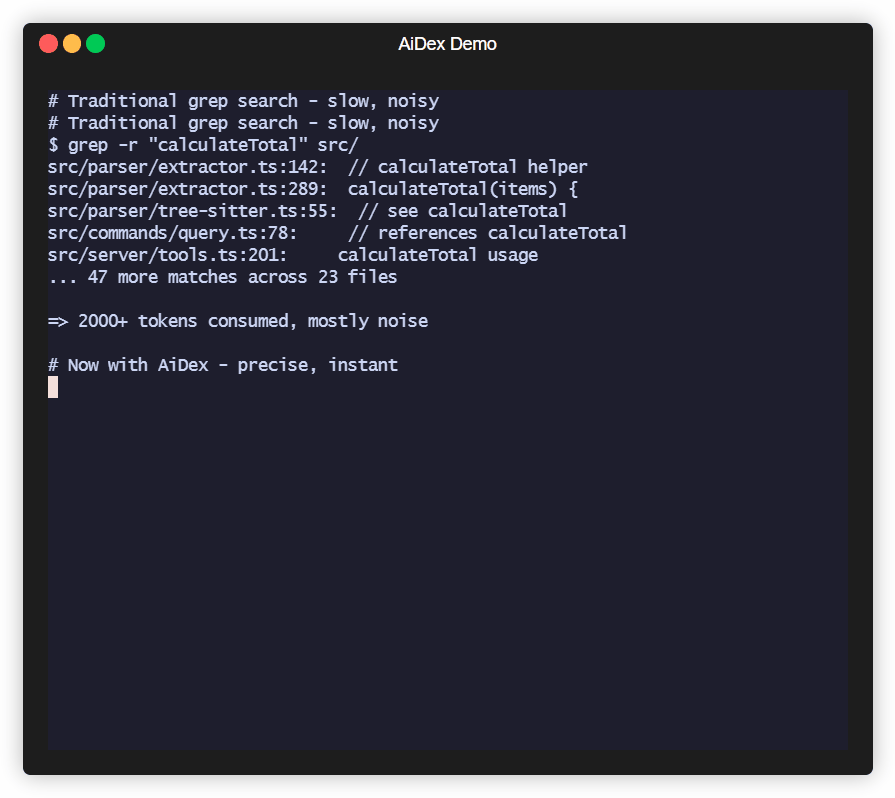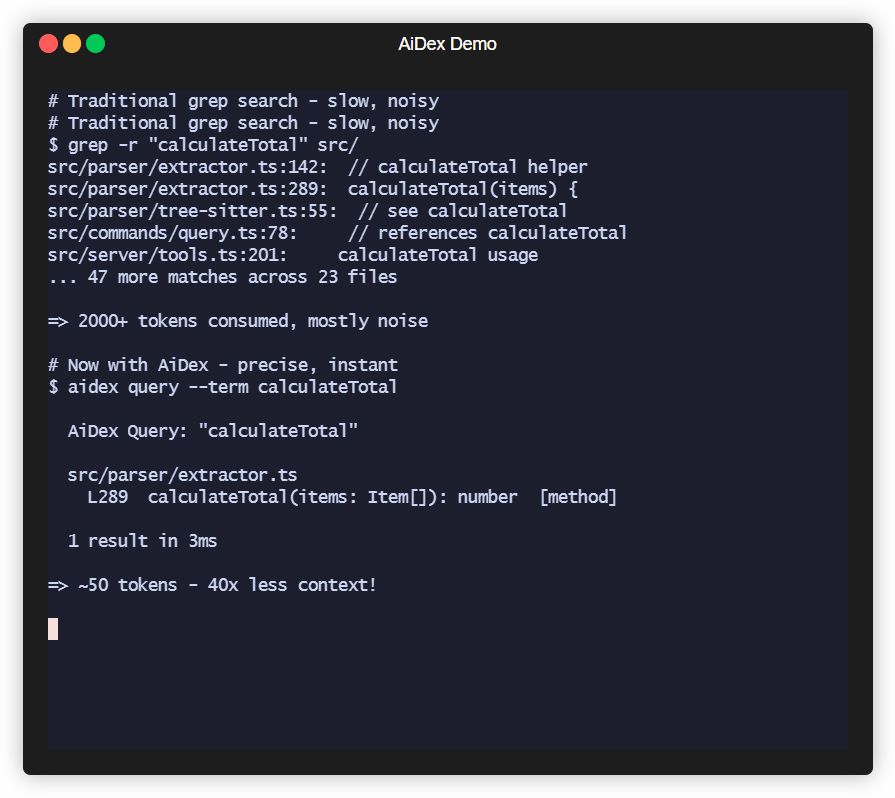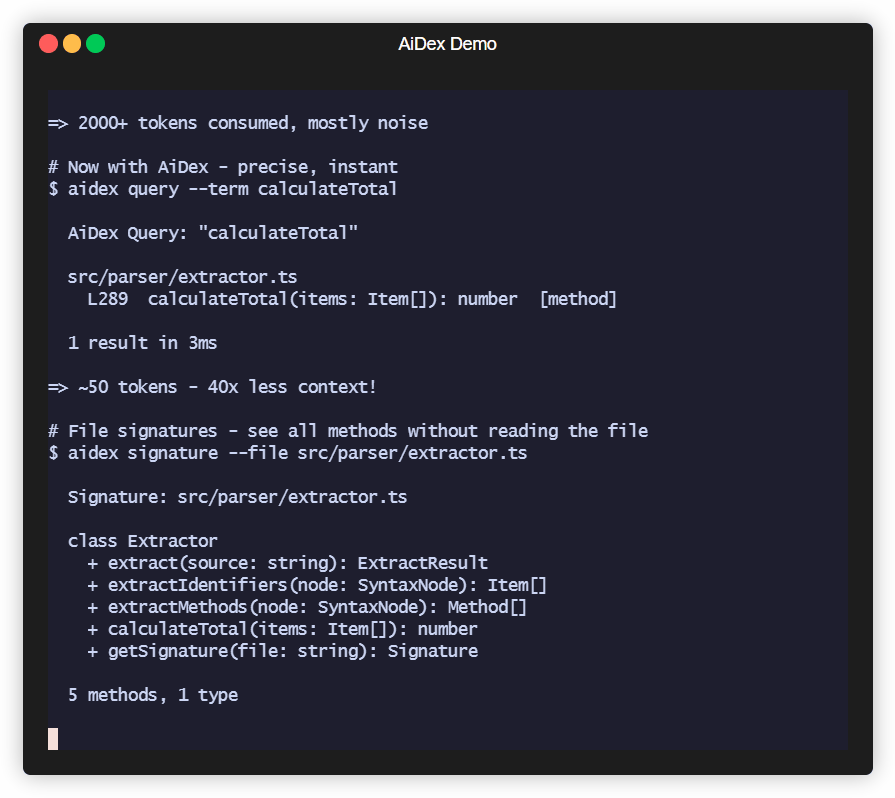
# After: precise results, minimal context
AI: aidex_query({ term: "PlayerHealth" })
→ Engine.cs:45, Player.cs:23, UI.cs:156
→ ~50 tokens, 1 tool callResult: 50-80% less context used for code navigation.
Why Not Just Grep?
| Grep/Ripgrep | AiDex | |
|---|---|---|
| Context usage | 2000+ tokens per search | ~50 tokens |
| Results | All text matches | Only identifiers |
| Precision | log matches catalog, logarithm | log finds only log |
| Persistence | Starts fresh every time | Index survives sessions |
| Structure | Flat text search | Knows methods, classes, types |
The real cost of grep: Every grep result includes surrounding context. Search for User in a large project and you'll get hundreds of hits - comments, strings, partial matches. Your AI reads through all of them, burning context tokens on noise.
AiDex indexes identifiers: It uses Tree-sitter to actually parse your code. When you search for User, you get the class definition, the method parameters, the variable declarations - not every comment that mentions "user".
How It Works
-
Index your project once (~1 second per 1000 files)
aidex_init({ path: "/path/to/project" }) -
AI searches the index instead of grepping
aidex_query({ term: "Calculate", mode: "starts_with" }) → All functions starting with "Calculate" + exact line numbers aidex_query({ term: "Player", modified_since: "2h" }) → Only matches changed in the last 2 hours -
Get file overviews without reading entire files
aidex_signature({ file: "src/Engine.cs" }) → All classes, methods, and their signatures
The index lives in .aidex/index.db (SQLite) - fast, portable, no external dependencies.
Features
- Tree-sitter Parsing: Real code parsing, not regex — indexes identifiers, ignores keywords and noise
- ~50 Tokens per Search: vs 2000+ with grep — your AI keeps its context for actual work
- Persistent Index: Survives between sessions — no re-scanning, no re-reading
- Incremental Updates: Re-index single files after changes, not the whole project
- Time-based Filtering: Find what changed in the last hour, day, or week
- Auto-Cleanup: Excluded files (e.g., build outputs) are automatically removed from index
- Zero Dependencies: SQLite with WAL mode — single file, fast, portable
Supported Languages
| Language | Extensions |
|---|---|
| C# | .cs |
| TypeScript | .ts, .tsx |
| JavaScript | .js, .jsx, .mjs, .cjs |
| Rust | .rs |
| Python | .py, .pyw |
| C | .c, .h |
| C++ | .cpp, .cc, .cxx, .hpp, .hxx |
| Java | .java |
| Go | .go |
| PHP | .php |
| Ruby | .rb, .rake |
| HCL/Terraform | .tf, .tfvars, .hcl |
Quick Start
Prerequisites
- Node.js ≥ 18 (check with
node --version)- macOS:
brew install nodeornvm install 18 && nvm use 18 - Linux: use your package manager or nvm
- Windows: nodejs.org
- If you use
nvm, the repo ships a.nvmrc—nvm usepicks the right version automatically.
- macOS:
1. Install
…