NocturnusAI
![]()


![]()
The context engineering engine for AI agents: send only what changed.
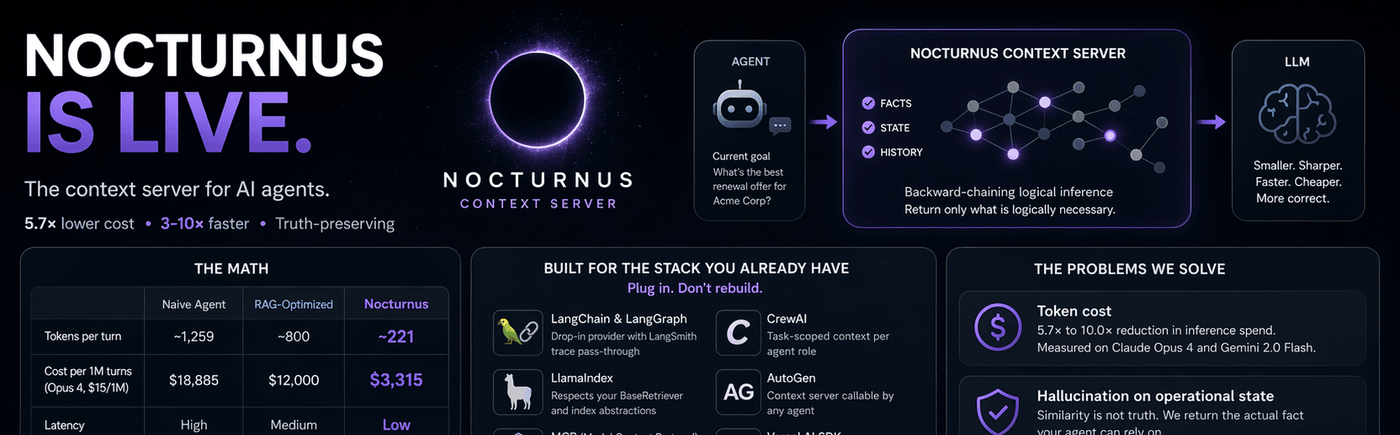
Before / After
# ❌ Without NocturnusAI — replay everything, every turn
messages = system_prompt + full_history + tool_outputs # ~1,259 tokens/turn
response = llm(messages) # $13,600/mo at scale
# ✅ With NocturnusAI — send only what changed
ctx = nocturnus.process_turns(raw_turns) # extract → infer → delta
messages = system_prompt + ctx.briefing_delta # ~221 tokens/turn
response = llm(messages) # $2,400/mo. Same accuracy.The Numbers
Measured on live APIs. 15-turn product support conversation. Real usage.input_tokens counts. Run it yourself.
| Naive replay | RAG-optimized | NocturnusAI | |
|---|---|---|---|
| Tokens per turn | ~1,259 | ~800 | ~221 |
| Cost per month (1K req/hr, Opus 4, $15/1M) | $13,600 | $12,000 | $2,400 |
| Latency | high | medium | low |
| Truth-preserving | no | no | yes |
Claude Opus 4: 5.7× reduction. Gemini 2.0 Flash: 10.0×. Full calculations.
Install
pip install nocturnusai # Python
npm install nocturnusai-sdk # TypeScript
docker run -p 9300:9300 ghcr.io/auctalis/nocturnusai:latest # DockerOr use the setup wizard:
curl -fsSL https://raw.githubusercontent.com/Auctalis/nocturnusai/main/install.sh | bashWhy Developers Star This Repo
- Reproducible token reduction — benchmark in the repo, methodology published, run it against your own workload
- Deterministic inference — same query, same result, every time. No embedding drift, no cosine similarity lottery
- Truth maintenance — retract a fact, all derived conclusions auto-retract. No stale context, no hallucination on operational state
- Plugs into existing stacks — LangChain, LlamaIndex, CrewAI, AutoGen, MCP, Vercel AI SDK, OpenAI Agents SDK, Mastra
- Benchmarkable against naive replay — numbers derived, not invented. Every claim traces to a notebook cell
Framework Quickstarts
| Framework | Integration | Link |
|---|---|---|
| LangChain / LangGraph | Drop-in NocturnusContextProvider, LangSmith trace pass-through | Docs |
| CrewAI | Task-scoped context per agent role | Docs |
| AutoGen | Context server callable by any agent | Docs |
| MCP | Spec-compliant server for Claude Desktop, Cursor, Continue | Config |
| OpenAI Agents SDK | Context middleware, no tool modifications | Docs |
| Vercel AI SDK | Edge-compatible adapter for Next.js, Nuxt, SvelteKit | Docs |
| Python SDK | pip install nocturnusai | Docs |
| TypeScript SDK | npm install nocturnusai-sdk | Docs |
How It Works
Three steps. Every turn.
- Extract — raw conversation turns → structured facts via LLM extraction
- Infer — backward-chaining logical inference finds only the facts reachable from the agent's current goal
- Return the delta — a
briefingDeltacontaining only what changed since the last turn
This is not vector search. It is not summarization. It is deterministic inference on a logic engine — Hexastore indexing, backward chaining, and truth maintenance.
The Working Loop
LLM required for natural-language turns. The examples below send raw text turns through an LLM to extract structured facts. If you start the server without an LLM provider, natural-language turns will return zero facts. See Quick Start for setup options, or use predicate syntax (e.g.,
"customer_tier(acme_corp, enterprise)") which works without any LLM.
1. First reduction: POST /context
curl -X POST http://localhost:9300/context \
-H 'Content-Type: application/json' \
-H 'X-Tenant-ID: default' \
-d '{
"turns": [
"user: Customer says they are enterprise and blocked on SLA credits.",
"tool: CRM says account is Acme Corp with a 2M ARR contract.",
"agent: Last week support promised to review SLA eligibility.",
"tool: Billing note says renewal is due next month."
],
"maxFacts": 12
}'2. Goal-driven pass: POST /memory/context
curl -X POST http://localhost:9300/memory/context \
-H 'Content-Type: application/json' \
-H 'X-Tenant-ID: default' \
-d '{
"goals": [{"predicate":"eligible_for_sla","args":["acme_corp"]}],
"maxFacts": 12,
"sessionId": "ticket-42"
}'3. Later turns: POST /context/diff
curl -X POST http://localhost:9300/context/diff \
-H 'Content-Type: application/json' \
-H 'X-Tenant-ID: default' \
-d '{"sessionId": "ticket-42", "maxFacts": 12}'Returns only added and removed entries between snapshots.
4. End of thread: POST /context/session/clear
curl -X POST http://localhost:9300/context/session/clear \
-H 'Content-Type: application/json' \
-H 'X-Tenant-ID: default' \
-d '{"sessionId":"ticket-42"}'Choose Your Surface
<details> <summary><b>Python SDK</b></summary>from nocturnusai import SyncNocturnusAIClient
with SyncNocturnusAIClient("http://localhost:9300") as client:
ctx = client.process_turns(
turns=[
"user: Customer says they are enterprise and blocked on SLA credits.",
"tool: CRM says account is Acme Corp with a 2M ARR contract.",
],
scope="ticket-42",
session_id="ticket-42",
)
diff = client.diff_context(session_id="ticket-42", max_facts=12)
client.clear_context_session("ticket-42")
print(ctx.briefing_delta)import { NocturnusAIClient } from 'nocturnusai-sdk';
const client = new NocturnusAIClient({
baseUrl: 'http://localhost:9300',
tenantId: 'default',
});
const ctx = await client.processTurns({
turns: [
'user: Customer says they are enterprise and blocked on SLA credits.',
'tool: CRM says account is Acme Corp with a 2M ARR contract.',
],
scope: 'ticket-42',
sessionId: 'ticket-42',
});
const diff = await client.diffContext({ sessionId: 'ticket-42', maxFacts: 12 });
await client.clearContextSession('ticket-42');
console.log(ctx.briefingDelta);{
"mcpServers": {
"nocturnus": {
"url": "http://localhost:9300/mcp/sse",
"transport": "sse"
}
}
}Use the context tool each turn for a salience-ranked working set. Pair MCP with the HTTP context endpoints when you need goal-driven assembly and diffs.
What Lives Behind The Workflow
When you do need backend mechanics, NocturnusAI provides them:
- Deterministic fact and rule storage
- Backward-chaining inference with proof chains
- Truth maintenance and contradiction handling
- Temporal facts with
ttl,validFrom, andvalidUntil - Multi-tenancy via
X-DatabaseandX-Tenant-ID - MCP, REST, Python SDK, TypeScript SDK, and CLI surfaces over the same engine
Quick Start
Docker (fastest)
docker run -d --name nocturnusai -p 9300:9300 \
--restart unless-stopped \
-v nocturnusai-data:/data \
ghcr.io/auctalis/nocturnusai:latestcurl http://localhost:9300/health # Verify it's runningDocker with Ollama (enables natural-language extraction)
docker run -d --name nocturnusai -p 9300:9300 \
--add-host=host.docker.internal:host-gateway \
-e LLM_PROVIDER=ollama \
-e LLM_MODEL=granite3.3:8b \
-e LLM_BASE_URL=http://host.docker.internal:11434/v1 \
-e EXTRACTION_ENABLED=true \
ghcr.io/auctalis/nocturnusai:latestFrom this repo
make up-ollama && make smokeCLI
nocturnusai # Interactive REPL
nocturnusai -e "context 10" # Salience-ranked working set
nocturnusai -e "compress" # POST /memory/compress
nocturnusai -e "cleanup 0.05" # POST /memory/cleanupDocumentation
Full docs: nocturnus.ai
| Start Here | The turn-reduction workflow |
| Context Workflow | Raw turns → optimize → diff → clear |
| API Reference | REST endpoints and response shapes |
| SDKs | Python and TypeScript client methods |
| Integrations | LangChain, CrewAI, AutoGen, MCP, and more |
| Benchmark | Measured token reduction on live APIs |
| Calculations | Every number, derived |
| How It Works | The extraction → inference → delta pipeline |
Docker Compose (advanced)
git clone https://github.com/Auctalis/nocturnusai.git && cd nocturnusai
make up # Server using .env.example defaults
make up-ollama # + Ollama (reuses host or starts bundled)
make up-monitoring # + Prometheus + Grafana
make smoke # Verify health + context endpointBuild from Source
Requires JDK 17+.
./gradlew :nocturnusai-server:run # HTTP server on :9300
./gradlew :nocturnusai-cli:run # Interactive REPL (JVM)
./gradlew :nocturnusai-cli:nativeCompile # Build native binary
./gradlew test # Full test suiteContributing
See CONTRIBUTING.md. Issues labelled good first issue are good entry points.
Security
Report vulnerabilities privately via GitHub Security Advisories. See SECURITY.md.
License
Business Source License 1.1 (SPDX: BUSL-1.1). Free for internal use — including internal production — inside your own organization. Offering NocturnusAI or substantial functionality as a product/hosted service to third parties requires a commercial license (licensing@nocturnus.ai). Converts to Apache 2.0 on 2030-02-19. See LICENSE and DISCLAIMER.md.
…